In one of the previous posts, I described how to use stable diffusion and Forge. Much has changed since then - it is unbelievable how quickly new models and tools come out. In this post, I'll be using the "ComfyUI" workflow and nodal graph type interface to drive the parameter setting for the generation, instead of Forge.
ComfyUI can do everything Forge can, plus more:
- Text to Image
- Text to Voice
- Image to Video
- etc
There's a couple of amazing things about ComfyUI:
- using the graph type interface provides great flexibility to build your own workflow
- it comes with many pre-defined nodes with which to build your own workflow
- there are already many workflows out there that you can start with - big shout out to AITRENEUR - find them on Patreon and Youtube
- If you generate an image with ComfyUI, the workflow becomes part of the meta-data - so sharing the image also provides the mechanism for recreating. Now there's something software engineers can learn from: the result encapsulates the means to rebuild.
- Most new models lately are proof of concepted in ComfyUI, with examples given

And a reminder that you will always have a command (shell) window running the actual payload, and a browser window with the UI - keep both visible!
Step-by-step: getting ready
FIrst - housekeeping. Get your stuff up to date: run the updater. Note: if you don't have ComfyUI at all, get the downloaders from AIntrepeneur.
Run comfyui_and_python_dependencies so as not to break torch.
NOTE: i had to upgrade my system RAM: 32Gb was not enough, and I'm using a NVIDIA 4070 TI and 12Gb VRAM.
Then start comfyUI:
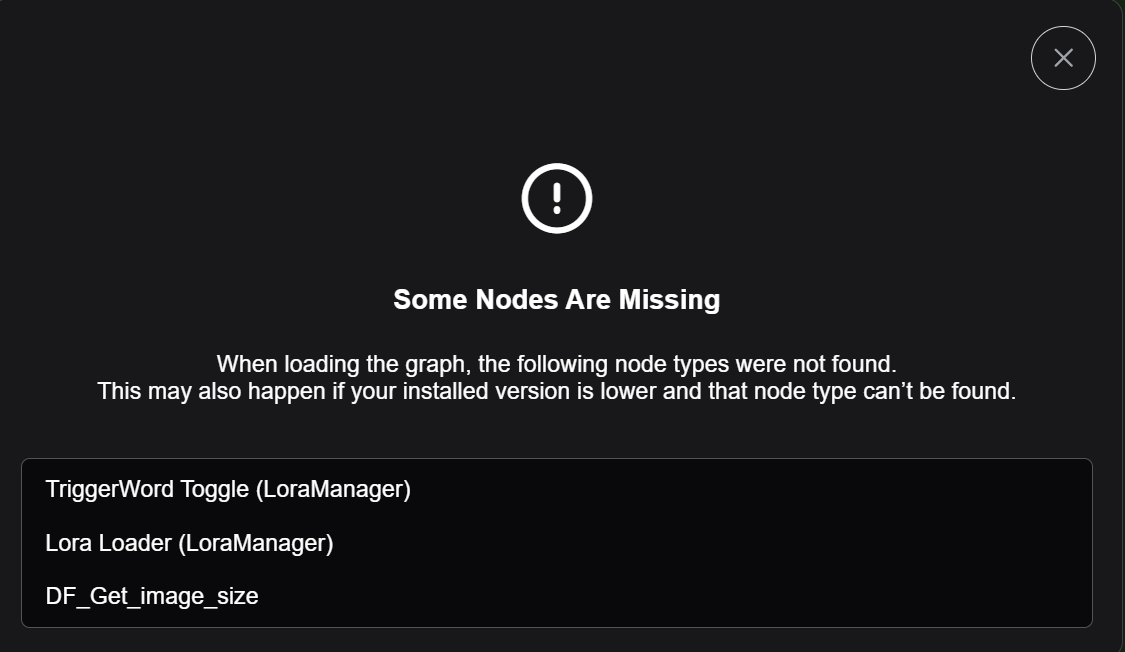
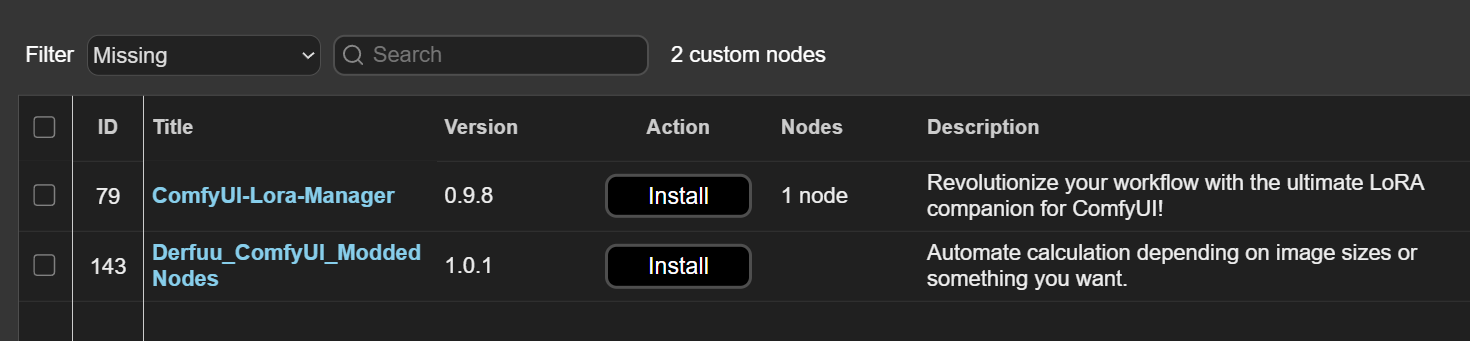
I used a .json file from a friend to get started. <add json> Dragging it into the ComfyUI window; it tells me this workflow is using nodes I've not yet downloaded, so I add them.
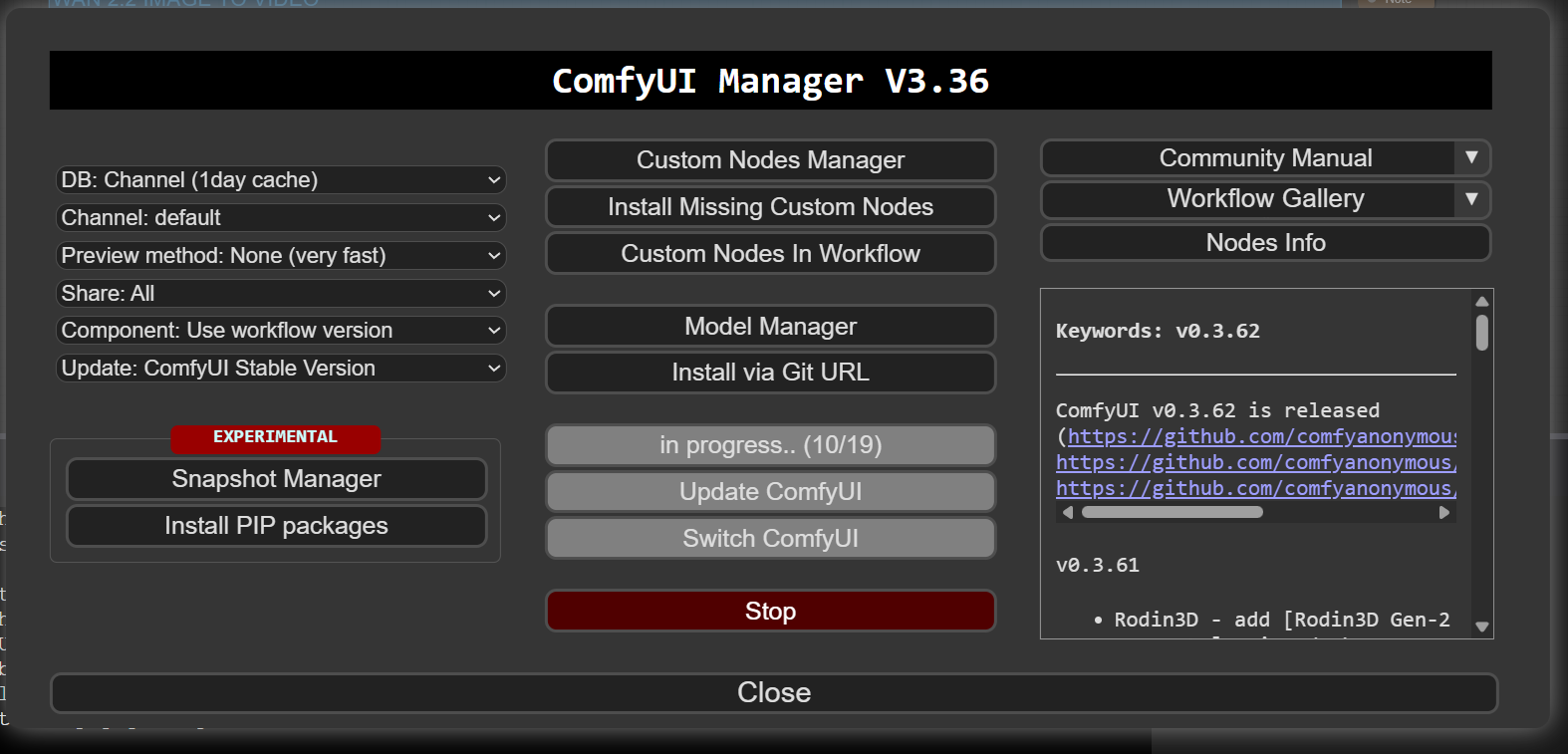
From the "Manager" tab at the top right of the window, select "install missing custom nodes" and answer all the questions, and then "Update All"
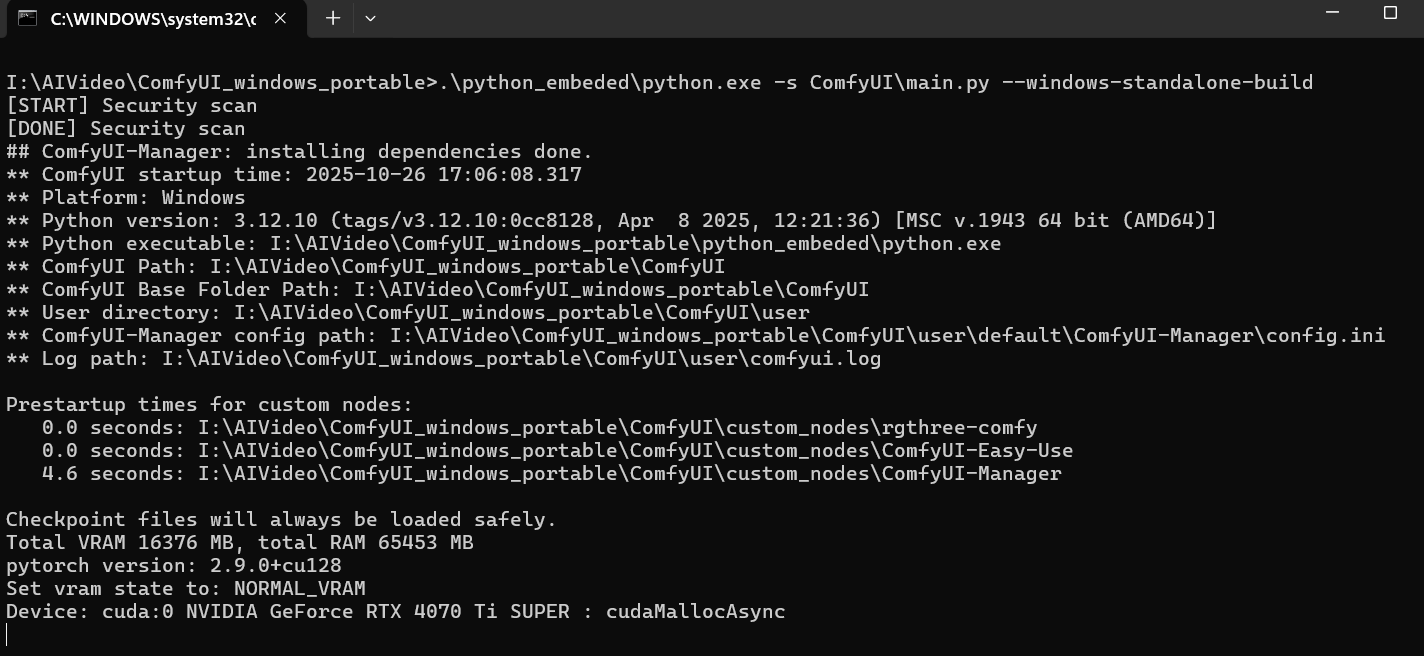
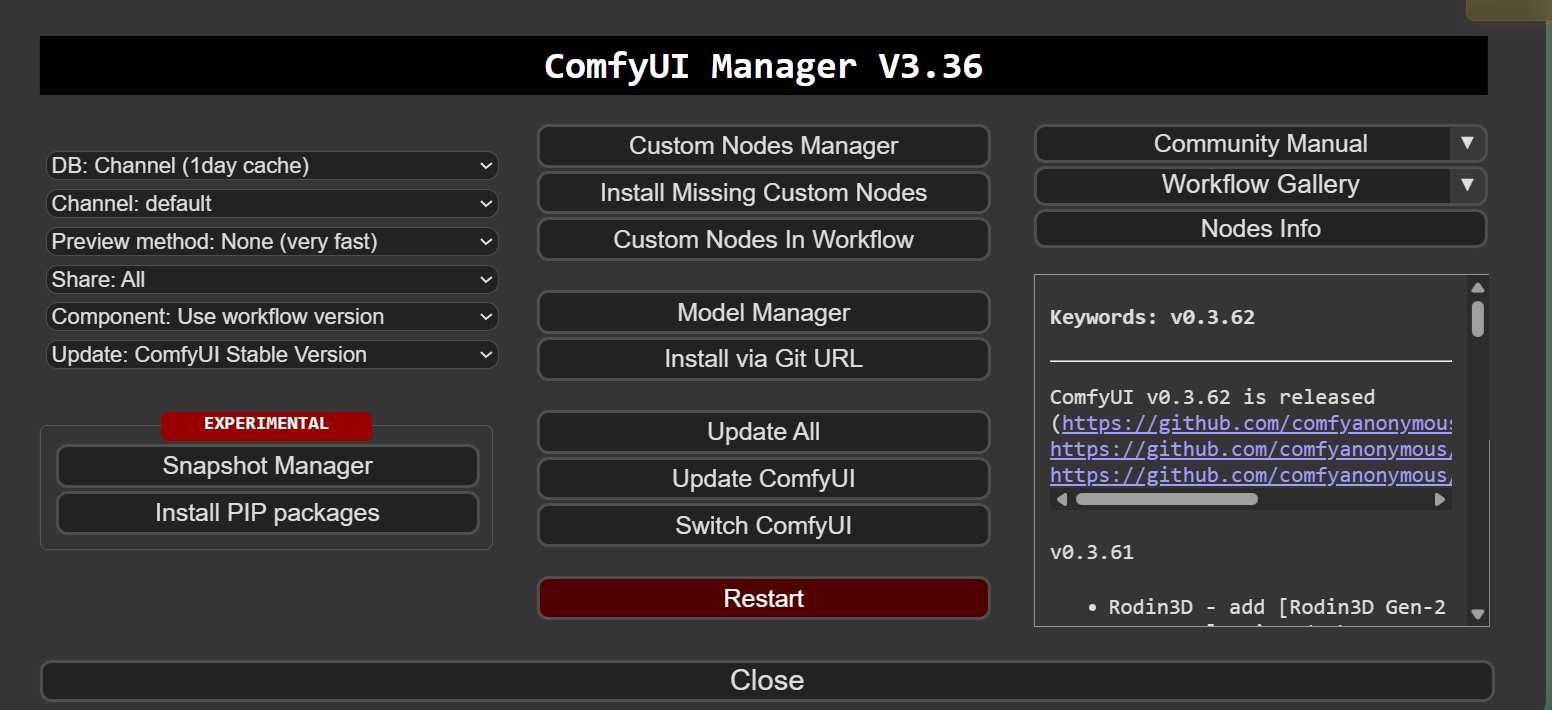
Using "Update All" to do a full refresh:
Note the menu at the top: the button with the capital "L" will navigate you to Civitai where you'll find a wealth of Loras to augment the model with. Also be aware that many of the Lora's will be NSFW so use the available filters and search options to find what you're looking for.
Also install Crystools from the Manager:

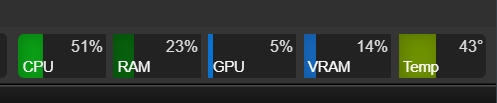
This will give you a nifty display at the top of your browser window with CPU and memory usage data:
Creating a video from an image
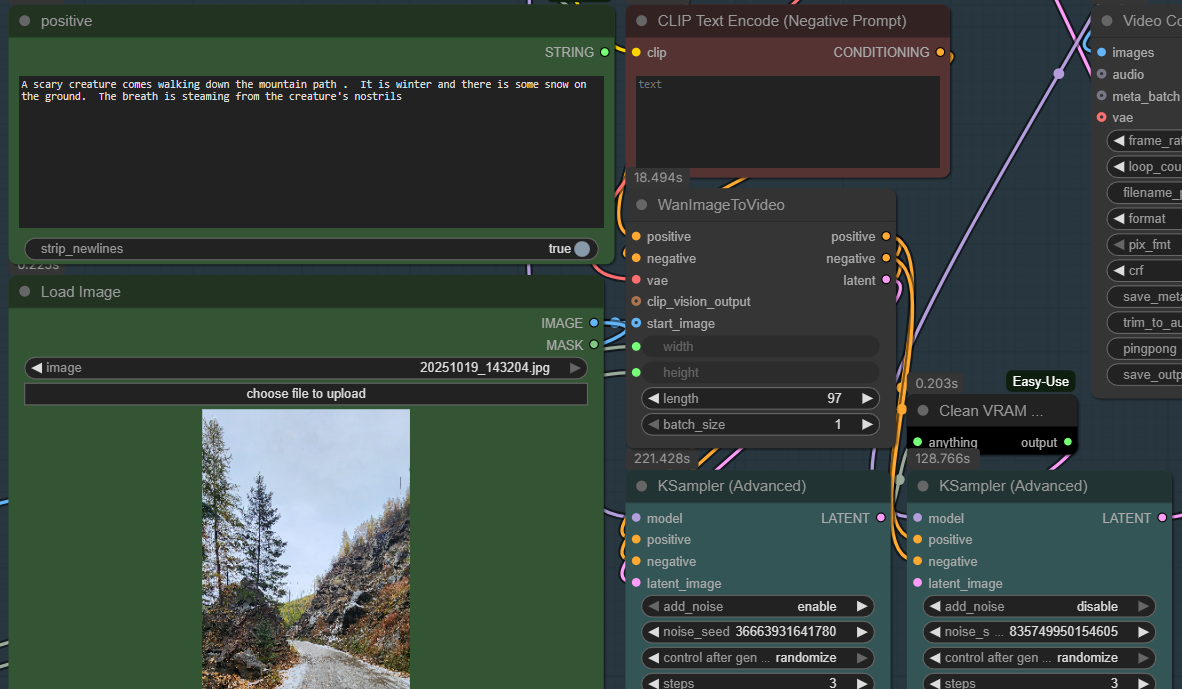
We will be using the WAN 2.2 model for Image to Video:
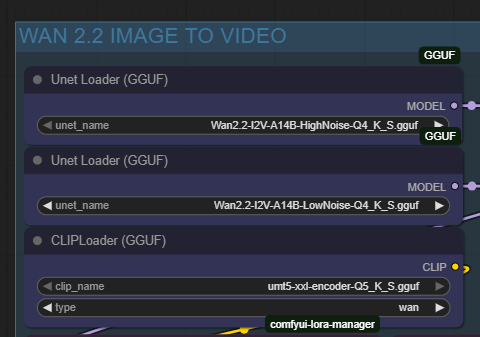
It will have two steps: "highnoise" which mostly focuses on the motion and "lownoise" which upgrades the quality of the image. Here are the settings I used; I'm using the Q4 model because I have an okay but not fantastic amount of VRAM. Use Q5 if you have mega VRAM memory.
As you can see, even with doubling my RAM, I'm using well over 50%, so good thing I spent the money on more system RAM :)

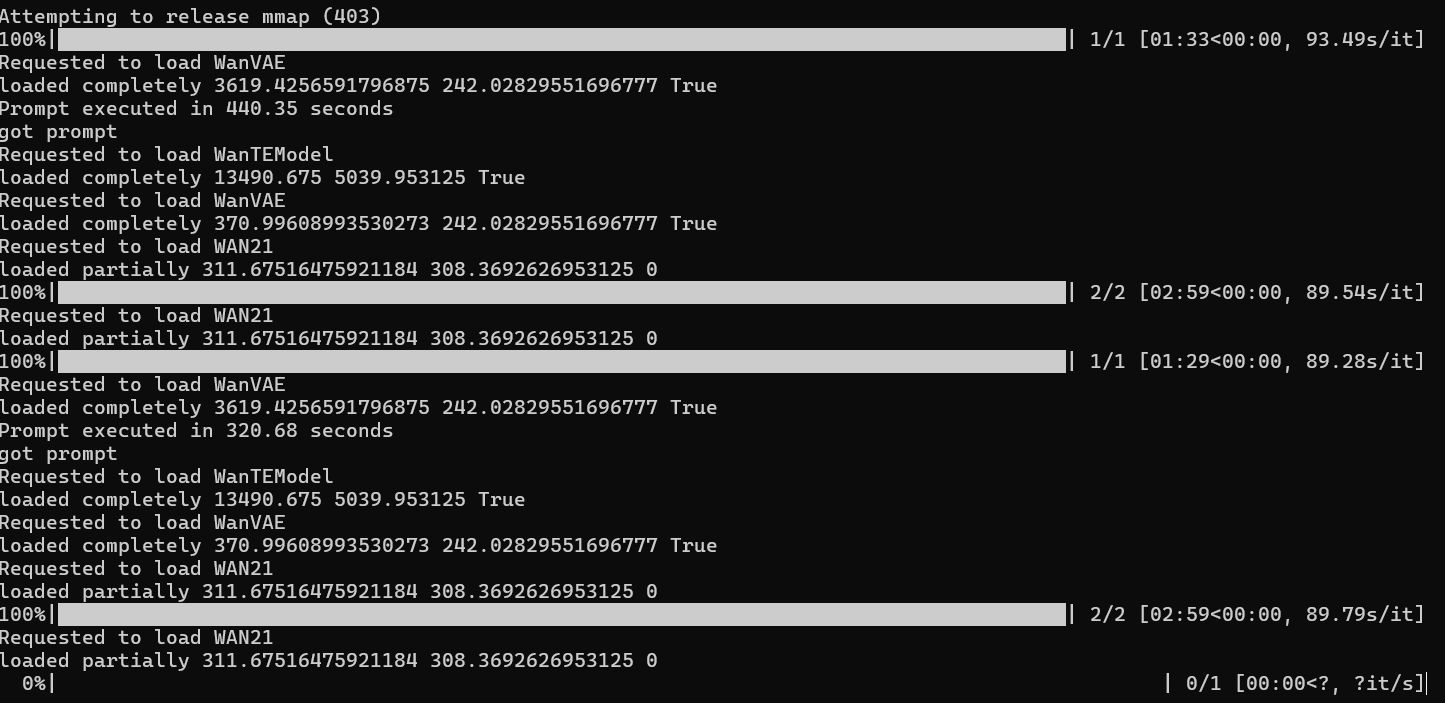
While you generate, keep an eye on the output in the command window and check for any errors.
For this particular workflow, all you need to change is the following - and all are in the middle of the workflow graph:
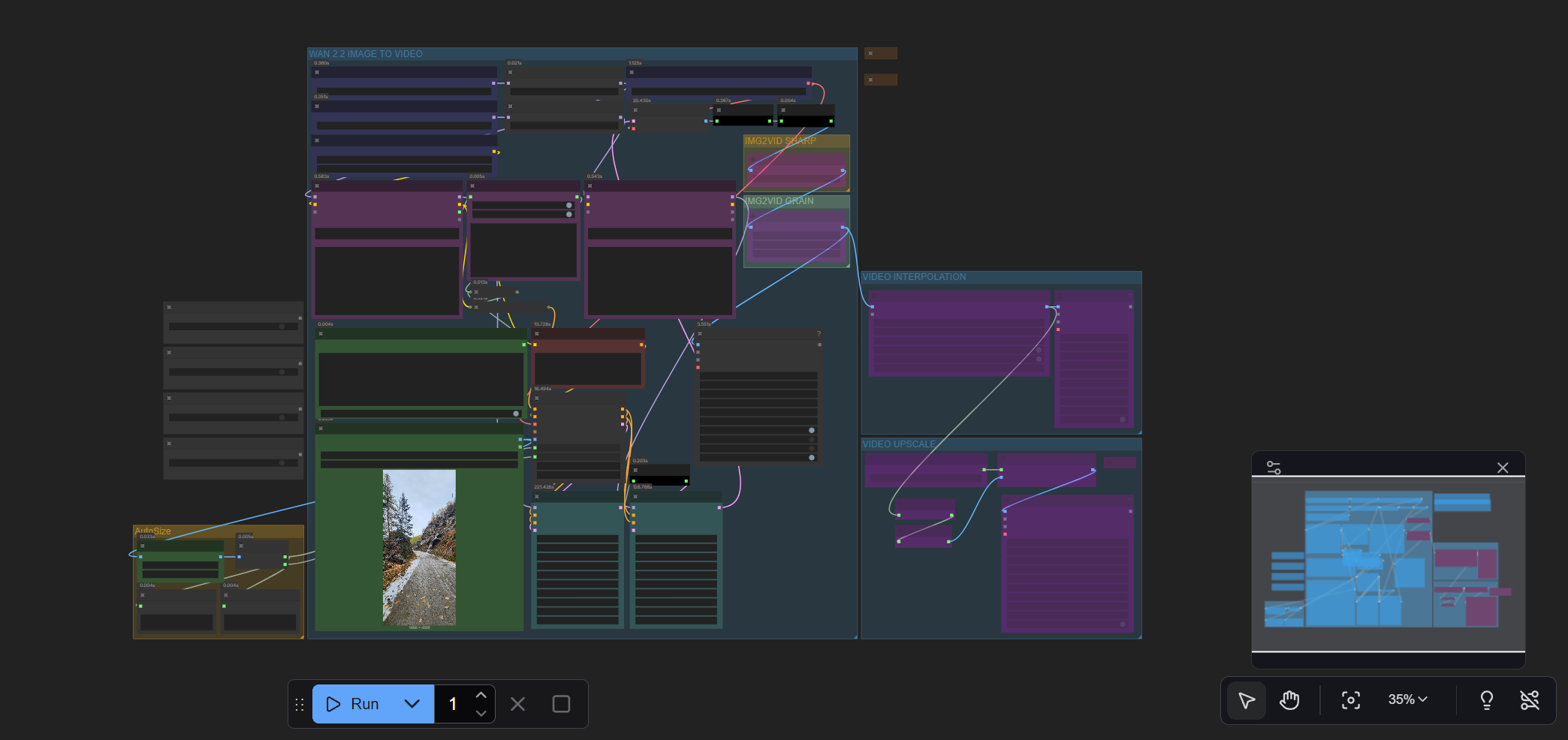
- the positive prompt
- the negative prompt (I haven't used any)
- drag your image into the "Load image" section. The image will set the scene as the starting frame of the video, and determine much of the outcome.
When you see the following message in your command window, the process is done:

The generated output can be found in the output folder:

I've left the 'lightning' steps turned on, am hearing it speeds up the process while not degrading the quality.
Here's the image. I used a portrait picture - which probably wasn't the best for a video - since the training data was most likely mostly landscape. Oh well.
Notes on good prompting
Here are some pro tips:
- put the subject first in your prompt.
- if the output is not what you want, try to think of what terms the model could've been tagged/trained with. Try synonyms. Try slang, try to make sure you use US terms for things, as most models are trained on the WWW and much of that is US based. Try to imagine what the type of image you want would have been tagged with in the training or source data - don't stick to literally to what you would call it. So if you want a motion that a ballerina would make, call it that - even if you don't want a ballerina or a ballet performance.
- be explicit. AI is a predictive model, not an artist. Tell it exactly what you want.
- practice and experiment. Learning to prompt and AI is like learning a new language. You have to start to understand how the model was trained and tagged, what types of descriptions and words resonate, and how to get the output you want. Too specific, and you get something boring. Not specific enough, and you don't get what you want. Learn to tell a story.
Add new comment