
If you have created or found a LoRA (see previous article), we can use Stable Diffusion's image generation from a text prompt ("TXT2IMG") to make awesomeness.
First, move the LoRA file to the Stable Diffusion folder. If you trained the LoRA yourself, take the output from the last epoch, which is the one that doesn't have the '000001' (for the epoch number) in the file name, and move it to the stable-diffusion/models/Lora folder.
Start Stable Diffusion run webui-user.bat in the STABLEDIF/stable-diffusion-webui folder
This starts a CLI which boots up the model and when ready, will give you a local URL to point your browser to:

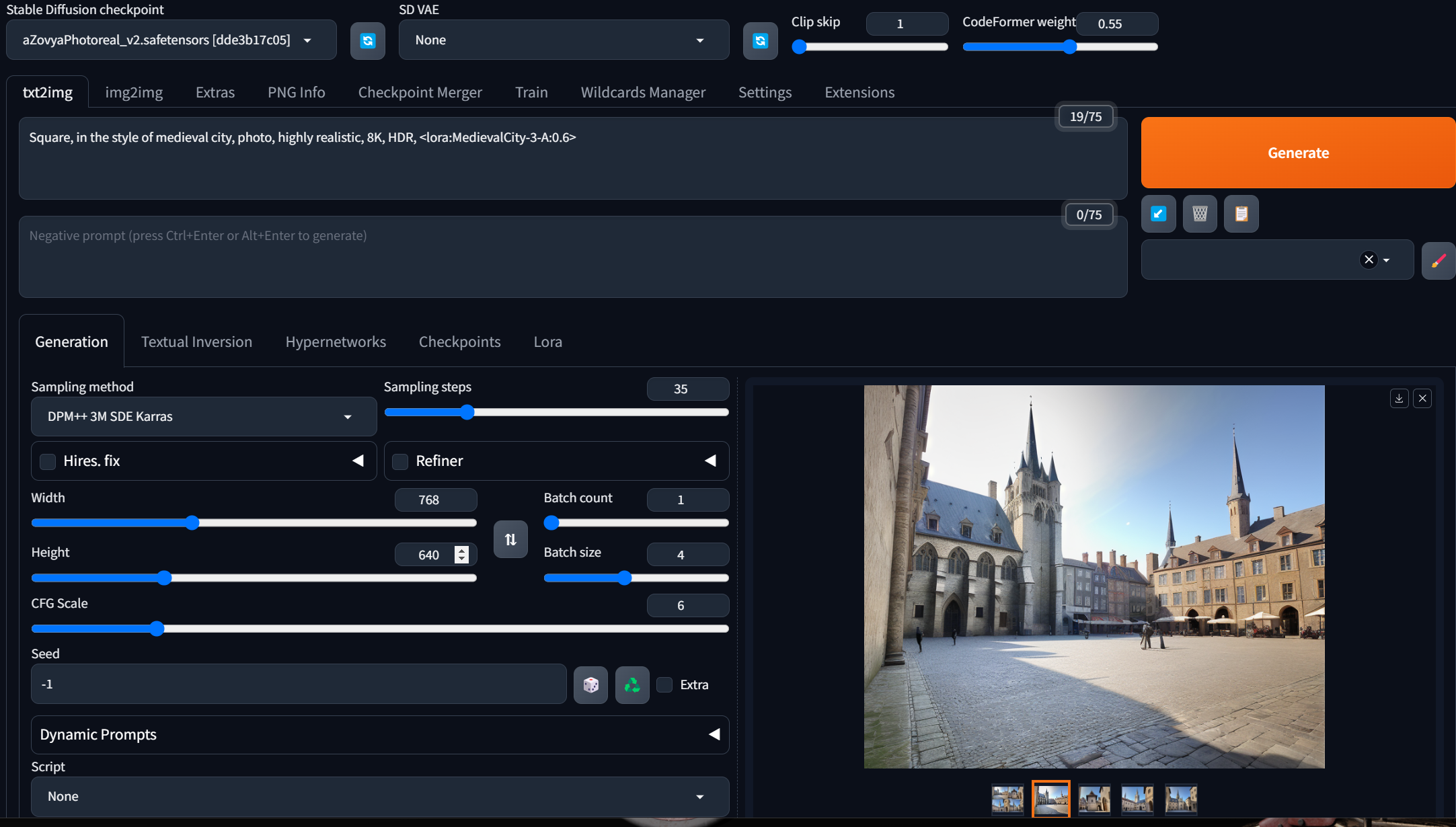

Note: at the very top of your screen you'll see the pre-selected model to generate with. Even though we trained with Stable Diffusion 1.5 to give the LoRA lots of compatibility, we've found that generating the images with it isn't optimal. There are many models to choose from, and since most are based on Stable Diffusion 1.5 they will work with your LoRA.
If you click on the 'Lora' tab in the middle of the screen, you will see your new Lora (and any others in that folder) and clicking on it will put the right syntax to add the Lora into your prompt, with a weight of 1.0.
Since this Lora seems pretty strong, I'm reducing to 0.6 <lora:MedievalCity-3-A:0.6>
Let me give a quick overview of the other knobs to twiddle on this screen:
- Top tab row, 'txt2img': your actual prompt. Because the base model is trained on a lot of random images, we've found that you can add "8K, HDR, UHD, realistic, photo" to the prompt, as many of the photos it will have learned from will have those tags for realistic images.
- Your negative prompt: the things you don't want. Again think about the fact that the net would have to know these as captions. So using a negative prompt of 'ugly image' would assume there are images in your base model captioned that way - unlikely! However, 'broken car' might exist.
- Sampling method: the secret math sauce; it is the method by which Stable Diffusion solves the equations and books written by people whose merest operational parameters I am not worthy to calculate. I asked my wise friend and they said to use this one: "DPM++ 3M SDE Karras". There are many opinions, and you can test with each. Because it is not an ancestral method, it will converge to an outcome, regardless of the number of steps. Ancestral sampling methods do not necessarily converge, so you might get very different outcomes at step 20 vs step 25, for instance.
- Sampling steps: how this works is dependent on which sampler. The tutorial linked about talks about it being progressive - but that is only true for certain samplers. For others, they may generate (from the 'latent', which is the noise pattern) that many images, and then do more clever math to compare and optimize. Again, I asked my clever friend and they said '35'.
- Width/Height: self-explanatory but the generation will do better with one or the other dimension. If you want a single person's portrait, more likely to come out well if you choose those dimensions. If you want multiple people, it tends to do better as landscape. A city - I will assume landscape, whereas my statues may come out better if I specify a portrait dimension.
- Batch count and Batch size: how many images to generate per batch, and how many batches to run. Your batch size is where the vRAM in your GPU really starts to make a difference - if you set it too big, you'll get an error. A high batch count just generates delayed gratification. So a batch size of '4' creates four pictures in a run, and with a batch count of '1' you're only generating four at once, and not eight.
- CFG scale determines how much weight the text prompt should have in determining the output. "0" is none. Six or seven is usually your sweet spot.
- The Seed seeds the random number generator that creates the latent, which is the starting 'noise' for the image generation. Each image in your batch will use a different seed. "-1" means pick a random number for the seed. You can see the seed that was generated underneath the generated image on your bottom right. With all the parameters the same, and the same seed, you should get the exact same image.
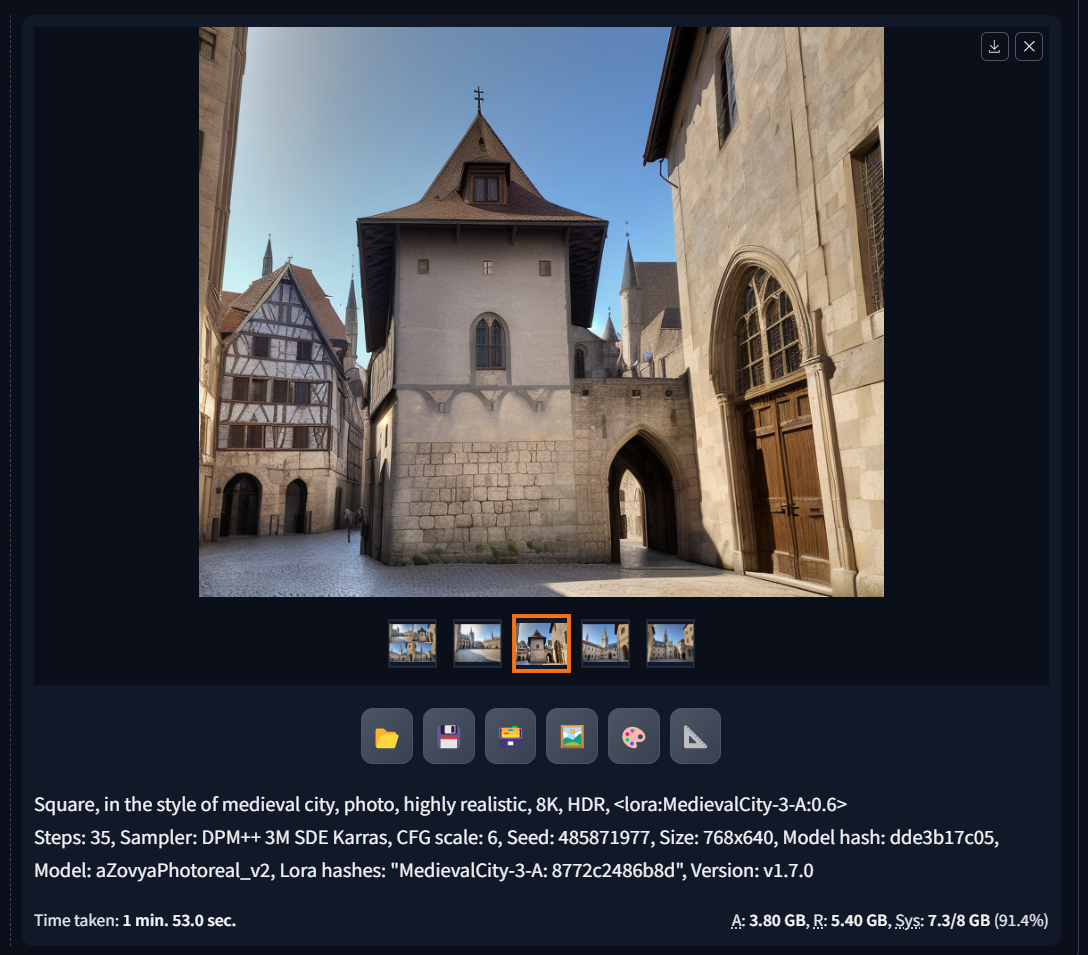
and that's it! The rest of the magic is in your creativity in modifying the prompt!
BTW Stable Diffusion saves all the images it generates, EVERY image, so at some if you're wondering why your file system is getting full.... check its 'output' folders :)

Add new comment